
Growing the Knowledge Gap: OpenAI's New Updates Are Important for Researchers in the Arts
Generative AI technology continues to evolve at breakneck speed... but many people and institutions, including universities, risk being left behind


On Tuesday, OpenAI released several key updates to its Large Language Models (LLMs) that made waves in the AI community. At their first Developer's Day conference, the company that created ChatGPT less than a year ago unveiled something akin to the Apple App Store to host tools that will allow ChatGPT to do all sorts of new and interesting things like connect to your OneDrive or become your travel agent. This follows quickly on the heels of last week's announcement that allowed users to upload whole PDFs and images seamlessly into the same model for processing.
But the most important developments were the technical updates aimed at developers using the company’s APIs. Sam Altman, the company's CEO, announced a new "turbo" version of their most advanced LLM that has a 128,000-token context window, meaning that it can process a whopping 92,000 words of text at a time. OpenAI also significantly increased the speed at which GPT-4 generates text while slashing prices on API calls by about 66%. They also rolled out a new vision API which allows developers to send huge numbers of images for automatic processing and analysis. After trying out the new APIs, I believe that for historians and those working in the social sciences and humanities, these will prove to be the most significant developments in AI since the release of GPT-4 back in March.
Why You Should Care about Context
On Tuesday, OpenAI updated its flagship GPT-4 so that it now has knowledge about the world up to April 2023. Most importantly, though, OpenAI's update effectively allows users to pass a full book or maybe seven academic articles at a time to a much faster and much cheaper version of GPT-4. This matters because it means that we are getting really close to the point when you will effectively be able to throw an entire customized library at ChatGPT and ask it to find the answer to a specific question.
True, Claude has had a 100k context window for some time, but Anthropic’s model is not as capable as GPT-4 when it comes to complex reasoning, and fewer people have access to it. Those of us in Canada still don’t have access to Claude at all! But from what I've heard, Claude does much better with texts that are about half to two-thirds its total window. Part of this is due to the way something called “attention mechanisms” work in LLMs: it's hard to get them to pay equal attention to everything all at once.
The new GPT-4 model with the enhanced context window is currently only available to developers, so you might not be able to try them yourself for a few weeks yet, but as I have API access, I spent the last couple of days seeing what they can do. I was especially interested in looking at how GPT-4 might handle a book-length text: would it be able to answer questions about the text as a whole or only discrete areas? Would it do better with shorter texts like Claude? Would it pay attention more effectively at the beginning than at the end?
The results are surprising and once again they've forced me to re-evaluate my conception of how (and how quickly) this technology will start to change our work. For both copyright reasons and ease of access, in my tests I used a draft version of the manuscript for my 2012 book The Last Plague: Spanish Influenza and the Politics of Public Health in Canada, minus two chapters (5 and 6) and all the notes/bibliography to get the 147,000-word text to around 90,000 words. I copied and pasted the text directly from Word into a simple chatbot interface I wrote in Python to interact with the API, and then asked it to read the above text, create a table of contents, and summarize each chapter in five points. I hit enter and three blinks of the cursor later, GPT-4-Turbo-Preview, as the model is called, began to respond. In about 8 seconds total, it read the book and produced an accurate annotated table of contents.

Next, I asked it to summarize the book, its argument, and the main evidence used to support the thesis. Again, it did a great job and in about 10 seconds. I then tried asking it more specific questions about the book, specifically the roles of Newton Rowell (a federal cabinet minister) and Helen Reid (a social reformer) in the creation of the Federal Department of Health. Both these people appear in the book’s final chapters, and while Rowell plays a relatively important part in the story, Reid appears in only a couple of paragraphs. I also chose them because, as might be expected, the base version of GPT-4 knows very little about their involvement in the creation of the Department of Health. After reading my book (literally in under 3 seconds), GPT-4-Turbo did.

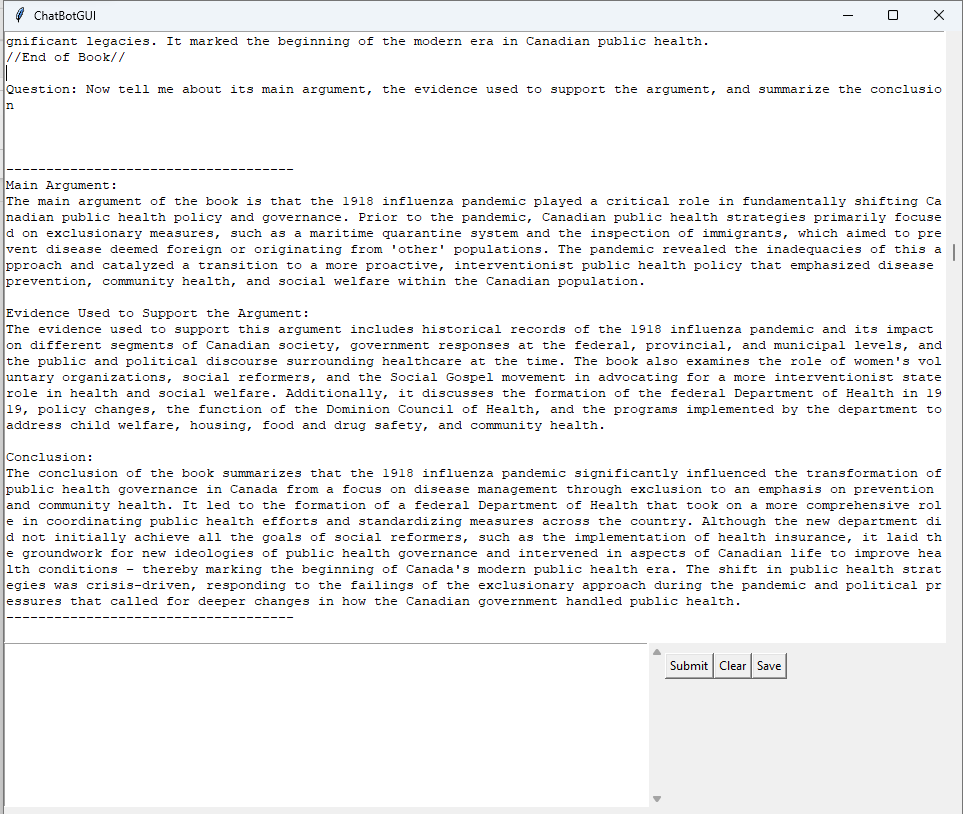
As a final test, I wanted to see how well it did at pulling specific, obscure statistical information from the latter part of the book. Somewhere towards the end of the text, I had written about the Federal Department of Health's early role in funding the building of family homes between 1919 and 1925, so I asked the model the following question: “Based solely on the above text, describe the Federal Department of Health's contribution to housing. Specifically, how large a fund did it make available to local governments for housing in 1919? How many municipalities had used this fund by 1924?” A few seconds later, it correctly responded: “Based on the text provided, the Federal Department of Health made a $25 million fund available to local governments to promote housing construction in 1919. This funding was available on the basis of 25 percent co-participation. By the end of 1924, 179 municipalities had tapped into the program to build more than 6,240 single-family homes across the Dominion.” Its answer was paraphrased from just three sentences on pages 182-83 of a 195-page book, right near the end where I expected the model's attention would fade. For the record, it took me much longer to find the actual passage in the printed book to cite it than it took GPT-4 to generate that answer.

Clearly, GPT-4-Turbo is capable of utilizing its full context window. It's also fast and cheap for what you get: each of my questions cost about $0.92 to answer. For comparison, if I had been able to send that much text to OpenAI's previously most capable model (which had a 32k context window but was never fully deployed), each query would have cost about $6.10.
It's the exponential nature of these changes that I find most staggering. Think about what this represents: in less than one year, OpenAI's top models have increased their text-processing capacity 32 times over, from about 4k tokens to 128k. If that pace continues—and even if it slows, there is no reason to think it won't still keep improving as processing power increases and the models become more efficient—by next year we are likely to see models capable of processing many hundreds of thousands of words of text at a time, perhaps millions. And yet, the cost is simultaneously falling—its fallen about 7 times over during the same period for OpenAI's top model. All the while new, more capable LLMs are being planned and trained by all the major players.
Why does this matter so much? Well, like many professional and amateur developers, for the better part of the past four months, I have been wrestling to balance a much smaller context window (8,000 tokens) with much higher costs, trying to find a way of ensuring that I can pass the “right” documents from a database of fur trade records to GPT-4. This involved many steps: fine-tuning models, trying out various types of semantic search, and Retrieval Augmented Generation (RAG). All of this ended up costing lots of money, sometimes as much as several dollars per query in order to get the best, most reliable results. Increasing GPT-4’s context window effectively solves most of those issues by allowing me to retrieve all the potentially relevant documents and tell a very capable model to "just sort it out".
Getting the GPT-4 Vision API to Read JPG Documents… Thousands of Them
OpenAI also gave developers access to its vision API on Tuesday. This means that people can now send thousands of images a minute to GPT-4 and use its vision capabilities to analyze the contents of things like photographs of documents—handwritten and typed—without having to OCR them first. To be sure, GPT-4’s vision capabilities are not perfect, but they will continue to improve. Although it struggles to transcribe handwritten or typed documents, it has no problem summarizing the contents or answering detailed questions about them. I’ve experimented with this a bit over the past few days, and it's really impressive, both in terms of the quality of the individual outputs as well as what happens when it's deployed at scale.
This is another thing that I used to think was still years away : you can now send 10,000 high-res JPGs of archival documents to GPT-4 and ask it to identify the specific images in which a concept or person’s name appears, much as I did above with the text of my book. But these are raw JPGs of archival documents, not OCRed text. At $0.007 per high-res image, this would only cost you $70.00, and it might take the better part of an hour to process through the API. In comparison, imagine hiring a research assistant to do the same task. A well-trained, competent graduate student might spend 3 minutes reading each page, for a total of 500 hours or about fourteen weeks of work—an entire summer. At $32.00 an hour, which is my institution’s new minimum rate for research assistants, that would cost around $16,000. So before Tuesday, this very common task would take about 500 times longer and cost 200 times more than it does now.
Knowledge Gaps and their Consequences
When you start to think this all through, it gets scary quickly. Even if generative AI doesn't get any better than it currently is (which it will), the effects of the technology are still going to be seismic. The problem is that it's developing faster than companies can actually build the advancements into their products. And so, most people don’t understand what AI can actually do at the moment—right now—because they haven’t had a chance to try its cutting-edge capabilities.
As a result, we're witnessing a widening gap between general awareness of AI’s capabilities and the actual state of the technology. The problem is that most people I talk to are still genuinely amazed that generative AI can write poems in the style of Bob Dylan. There is a lot of road between that place and AI’s new ability digest an entire archive in a few minutes. AI is simply starting to outrun many people’s imaginations. It's a bit like trying to describe the iPhone’s capabilities to someone whose only experience with cellular technology was a fleeting encounter with an early 1990s car phone. All this is happening so quickly that most people won't realize the magnitude of the transformation until long after their world has been completely engulfed by the change.
Nowhere is this truer than in academia. Many institutions are still in the initial stages of reacting to the technology as it existed a year ago. Committees are being formed, while others are holding their first meetings, all to discuss people's experience with a version of the technology—ChatGPT GPT-3.5—that has already been surpassed many times over. In effect, they’re still talking about the technology as if it is a theoretical thing without the full understanding that it poses a very real, existential threat to our whole raison d'être as higher educators.
Not everyone is going to get caught in the dark, though. As in any revolution, there will be winners and losers. Surprisingly, the Canadian federal government seems to be ahead of many schools, as they released some very permissive guidance on AI usage more than two months ago now. It is notable too that unlike many universities, that document calls on employees and the general population to engage with AI, to use it to inform policy discussions and to write emails, proceeding with caution when making decisions or engaging with the public. Given the Canadian government's poor track record on technology issues of late, it worries me that they seem to be outpacing our institutions of higher learning in realizing that, like it or not, the technology is here to stay and can actually be very useful.
In Canada, some institutions like McMaster University have been quicker than others to issue guidance on the use of AI in teaching and research. But because not every university is taking the same approach, gaps are widening. There will come a point, though, when the distance between the technology being used in the world and the awareness and understanding of that technology by staff, faculty, and administration grows so large at some institutions that it will become unbridgeable. When this happens, it will almost certainly be the early adopters that thrive. It may well prove impossible for latecomers to catch-up which will be disastrous in a world already beset by declining enrolments and government pressures to become more "workforce relevant".
So as exciting as all the recent updates are, I fear they move us closer to a point where those paths are beginning to irrevocably diverge.
That is a really good question and one that has yet to be sorted out.
I think it will depend on a whole variety of factors. Some archival documents will by subject to copyright while many will not. Some archives already have prohibitions on sharing images without their permission and that is usually written into their terms of service or user agreements (the things you agree to on website or the documents you sign when you take pictures at an archive). And it will also vary depending on the software you use and where you use it.
If you run a local LLM like Llama2 on your own computer, which I do for some cases, the ethical questions would be no different than whether you use Adobe or MS Photo to view the images or Excel or SPSS to compile data. You're just using a software program to conduct private research on your own computer. There is no transmission or sharing of the records.
I'm not a legal expert but I suspect the same is true if you use OpenAI's API to process images or data because it is a secure, private gateway and under their terms of service they do not retain any of the information that is sent to the API nor will they use it for training purposes. So if you are using the API for private research, I suspect that the legal and ethical issues would be no different than taking a picture of a document with an iPhone (which stores those images on the cloud), putting a document into word (which is now cloud based too), storing those files on your OneDrive, sending them to Transkribus for transcription, using Google Translate, or putting them into DropBox. In those cases, as long as the LLM does not store or use the data and is secure, its just another piece of software. That said, in my experiments with the API (as distinct from locally run models) I have been careful to use open-access, publicly available, and copyright free archival records. That is also why I used my own book manuscript for the tests above: I kindly gave myself permission to send the entire text to the API.
Inputting images of archival documents or the texts into ChatGPT is a bit dicier as it is not a "secure" interface and unless you have the paid version and change your settings to tell OpenAI not to use your conversations for training purposes, they will. Again, when I do this I am very careful to think about whether I know whether I have the right or not to input the image into ChatGPT.
But here is a really important thing I know that you cannot do: if there are any specific use restrictions on your records or prohibitions against electronic storage and retransmission, especially if your records contain private or classified data or are information subject to the Canadian Privacy Act, you most definitely cannot send them to an external LLM via an API or a browser based program like ChatGPT. But it’s important to keep in mind that for those types of cases, such restrictions are not limited to LLMs: people would also be prohibited from storing those types of records on any cloud based server like iCloud, OneDrive, etc. or using cloud-based software (Adobe, Word, etc) to do things with the documents.
The case of copyrighted materials, including PDFs of books and articles, may sound clearer but it will again depend at least in part on the terms of service under which you acquired them in the first place. Most people probably don’t think about this when they run paragraphs through Google Translate, email a paper to friend, or save a copy of an article to their OneDrive but we are more conscious of it with a new technology like LLMs. Here the law remains very much unsettled which is why authors and creators are suing companies like OpenAI.
An interesting development is that OpenAI also announced on Tuesday a new Copyright Shield program which says: "OpenAI is committed to protecting our customers with built-in copyright safeguards in our systems. Today, we’re going one step further and introducing Copyright Shield—we will now step in and defend our customers, and pay the costs incurred, if you face legal claims around copyright infringement. This applies to generally available features of ChatGPT Enterprise and our developer platform." (https://openai.com/blog/new-models-and-developer-products-announced-at-devday) This is similar to a program that Google unveiled awhile back. It’s a pretty sweeping indemnification which suggests to me that OpenAI is fairly confident that using LLMs to process even copyrighted materials will be upheld in the courts. We’ll see. Whether its ethical to do so is a very different matter.
So a really good question…maybe I’ll turn this into a blog post. I think best practice is to ensure you always adhere to any relevant terms of service and user agreements that apply to your documents. Don’t send legally restricted or classified information to any cloud service. Be mindful of what you are doing with an LLM and where you are using it (locally, via API, or in a web-browser).
Heard your podcast and was enthused!! My project is tiny, getting a maybe 500 pages of Homeowners Association Documents Into a trained chat. I have been using two different products: Dante and My AskAI. They both make it pretty easy, but I am concerned about accuracy and your experience shows me "behind the curtain" - helps me understand lots better.
A friend and Neighbor is a Board Member of the Museum of the Fur Trade in Nebraska. I will be bending his ear soon about AI and their documents.