
Making the Infeasible Practical in Historical Research
Developing AI Research Tools for Historical Research and General Release


In my experience, one of the biggest misconceptions about generative AI is that it must involve a one-on-one conversational interaction with a chatbot. What most people don’t realize is that generative AI’s most promising applications have nothing to do with chat interfaces. Instead, they almost all involve using the underlying LLM to do “thinking” tasks very quickly. Think: using AI to do hundreds of complex things—summarization, translation, transcription, keyword categorization, information extraction, etc—in a few seconds.
Over the next few weeks, I plan to make a few programs I’ve been developing available to researchers. These include a program that automates the transcription of handwritten documents with a similar level of accuracy to human transcribers and another that takes notes on archival documents. The idea is that researchers will be able to download either the code or an executable version of the software and customize it to their own purposes. These are not chatbot type research assistants but simple AI-enabled programs that can be easily integrated into any research pipeline. In fact, I think these task specific types of tools focused on scaling-up and speeding up the research process will have a much greater effect on what we do than autonomous research assistants, at least in the near term.
AI Enabled Research Software
AI-enabled research software involves sending many things (like text or images) to an Application Programming Interface (API) where the LLM processes it according to a set of instructions. The software then receives the LLM’s response back and does some more processing before saving it to a text file or storing it in a database. In these types of applications, you’ll rarely interact directly with the underlying AI engine at heart of the program but it’s doing all the heavy lifting.
Let’s think about what this might look like for historians. Imagine we are writing a medical history and wanted to determine how long it took soldiers in the First World War to be evacuated from the front to England by the type and location of a wound. It’s a solvable problem as all 620,000 First World War personnel files have been digitized by Library and Archives Canada. But generating the data by hand would take a long time: because only 1 in 4 Canadian soldiers were wounded and there is no master list of who they were, you would need to start with at least 1,600 personnel files chosen at random in order to get the 400 wounded men necessary to construct a basic sample. A year ago, the only way to do this would have been to go through something like 80,000 pages of records one by one, which would have taken many, many weeks.



Thanks to GPT-4o, the new “omni” model recently released by OpenAI, it’s now possible to do this in a few minutes. GPT-4o is faster and much cheaper than its predecessors GPT-4 and GPT-4-Turbo, but it is also far better at analyzing images. It can often transcribe handwriting nearly verbatim and can also decipher documents which feature a mixture of handwritten and typed text.
It has it’s limitations too. Sometimes the AI will miss something or confabulate, it is true. But in my experience, the best LLMs make no more mistakes than humans including myself and student research assistants. Its mistakes are often weirder, but not more frequent.
First Steps
Whether a human or LLM tackles our First World War research question, it will involve creating some sort of database or spreadsheet. In this case, we’d probably create a spreadsheet with seven columns: Name, Wounded (Yes/No), Date of Injury, Type of Injury (GSW/SW/Gas etc), Date of First Hospital Admission, and Hyperlink to the Document. This last column will let us verify the accuracy of the data afterwards by providing a quick link to the underlying document. When we populate the database with the data, we should have 1,600 rows, one for each soldier; around 400 of those should have relevant data. We’d then crunch the numbers and get our answer.
So let the analysis begin! If I tried to do this myself, my experience suggests I could probably manage to skim 8 pages a minute, an average that would include flipping past dozens of obviously irrelevant pages very quickly while spending several minutes parsing unclear handwriting, resolving contradictions, and entering the data in other places. That means it would take roughly 20 eight-hour days to get my results.
By automating the research process, we could write a program that gets this down to a couple hours at most. First, we would need to write a conventional Python script to choose the 1,600 personnel files from the LAC website at random, download them, extract the images, and then send them to an LLM along for analysis. If this sounds complicated, you should understand that a novice programmer could write the code to do the first three tasks in only a few minutes. The last part requires a bit more thought and is where the AI comes in, not because the coding is any more complicated (it isn’t), but because LLMs don’t work in a conventional way.
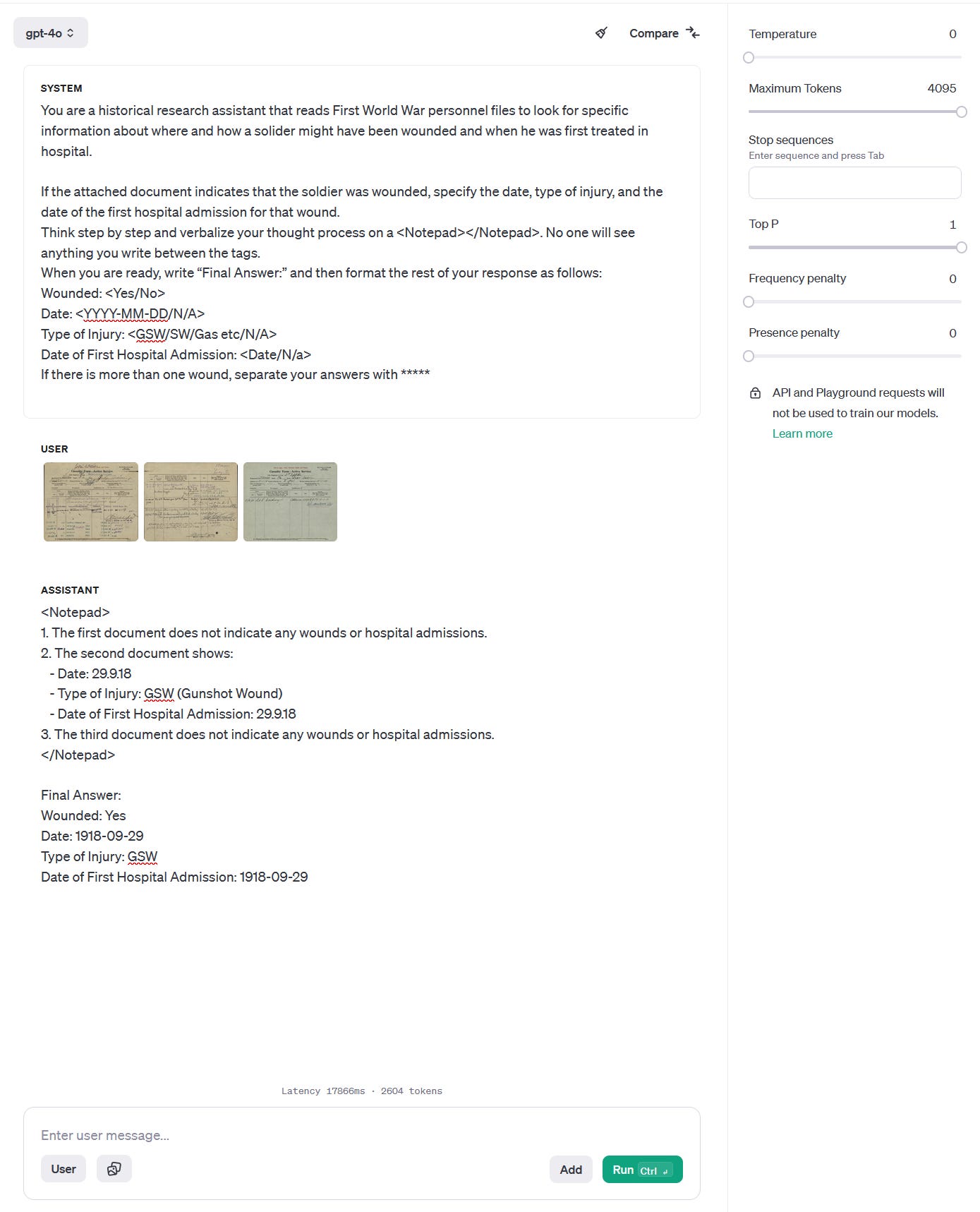
Envisioning What the AI Does (and How it Does it)
To get a sense of what I mean, imagine for a minute that the LLM is a remotely located human research assistant with whom you can only communicate via email and a shared Dropbox folder. Unfortunately, the Dropbox folder is also very small and can only hold somewhere around 5 high-res images at a time. It cannot be expanded so you need to send the assistant materials in small batches. To complicate matters, although our research assistant is highly capable, they have a condition which prevents them from forming memories. After they complete each task they email you the response and them promptly forget what they just did. This poses something of a problem as each personnel file is around 50 pages long.
Even within these constraints, LLMs can do a lot of useful things for researchers, but we need to understand those limitations and play to their strengths, namely speed and efficiency. There are lots of ways we could setup our program, but the simplest would be to send each personnel file to the LLM a few images at a time along with a series of instructions demanding a response that we can process automatically in python.
When communicating with an LLM via an API, which operates like the email/Dropbox communications above, we can send our virtual research assistant both textual instructions (often as a “System Message”) along with the images for it to analyze. In our case, we might write something like:
“You are a historical research assistant that reads First World War personnel files to look for specific information about where and how a solider might have been wounded and when he was first treated in hospital.
If the attached document indicates that the soldier was wounded, specify the date, type of injury, and the date of the first hospital admission for that wound.
Think step by step and verbalize your thought process on a <Notepad></Notepad>. No one will see anything you write between the tags.
When you are ready, write “Final Answer:” and then format the rest of your response as follows:
Wounded: <Yes/No>
Date: <YYYY-MM-DD/N/A>
Type of Injury: <GSW/SW/Gas etc/N/A>
Date of First Hospital Admission: <Date/N/a>
If there is more than one wound, separate your answers with *****"
In these instructions, we clearly explain the task, tell the LLM what to do, and ask it to “think step by step” to explain its “thought process”. Strange indeed but research has shown that this increases accuracy and reduces hallucinations significantly, especially when reasoning over content. We also specify the specific form we want the answer to take because we can then parse the response in Python, meaning we use code to extract specific parts (we could do this even more effectively through a markup language called JSON but that is a bit more complicated than I want to get here).
Costs and Time
After we get the response back, we would use python (or another LLM) to automatically collate the answers, remove duplicates, and populate the spreadsheet. If this sounds time consuming or complicated, once it is setup it’s extremely quick: OpenAI’s API allows 10,000 requests per minute (meaning images processed in our case). At around 1,000 tokens (around 750 words with each image being the equivalent of 500 words) a request and $5.00 per million tokens, it would cost around $400.
To reduce the cost and time involved, we would probably add another step to the process. By sending each page to a smaller, less capable but much cheaper model like Anthropic’s Claude Haiku first, we could then send only the most relevant documents to the more expensive GPT-4o. While Haiku is not as good as GPT-4o at parsing handwriting and extrapolating from information, it is good at doing things like recognizing whether a given document is an example of one type of form or another or just determining whether it contains information relevant to a given topic.
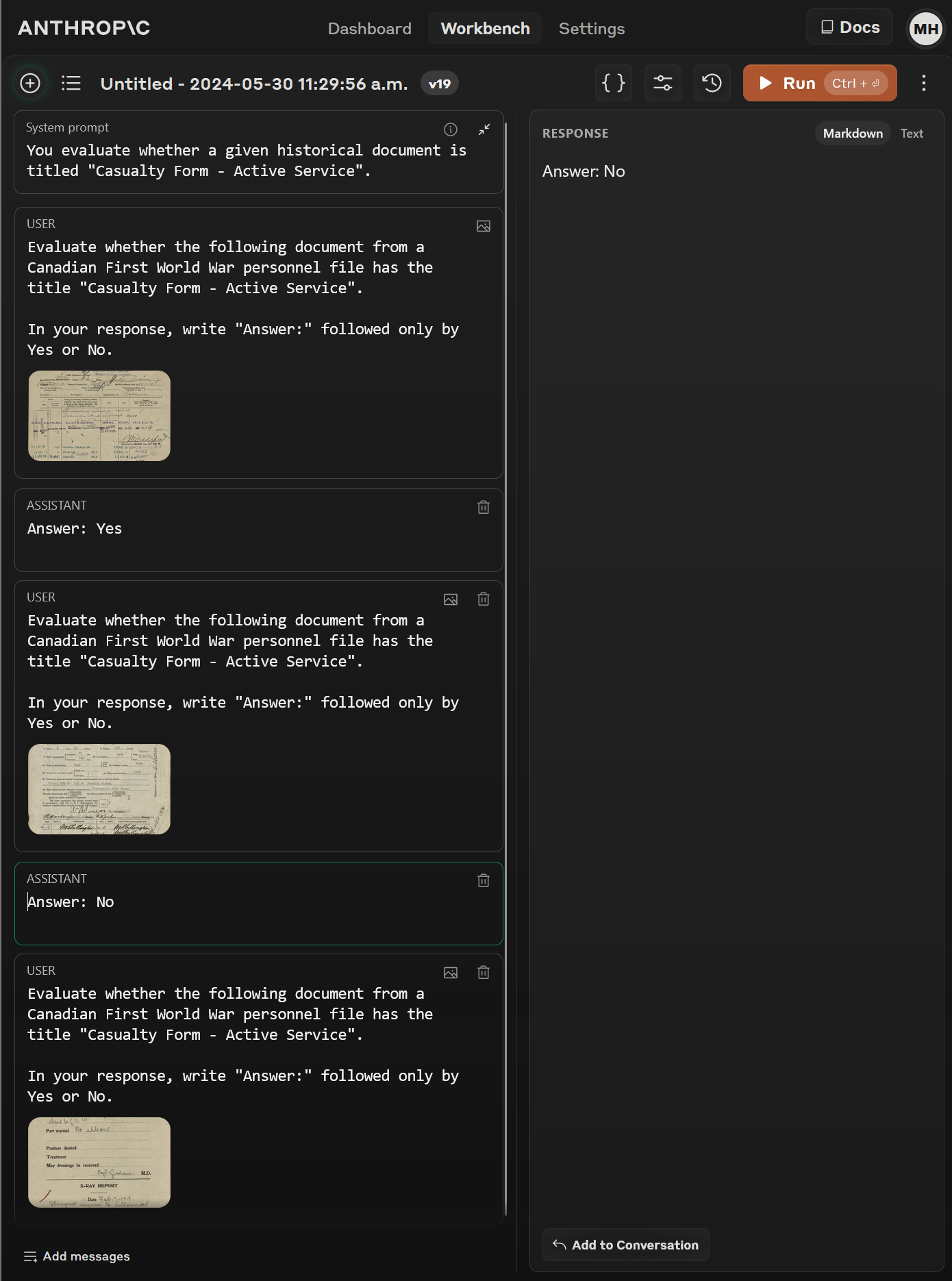
This sort of pre-processing would involve giving instructions to Haiku about which documents in each personnel file are relevant to our research question. In our case, we could probably restrict the analysis to the Casualty Form – Active Service which should contain all the relevant information. In each API call, we would provide Haiku with an example of the form along with the image in question and then give it a simple question to answer: is this document a Casualty Form – Active Service similar to the examples appended below? If so, our code would send it to GPT-4o for a more thorough analysis, and if not we’d move on to the next image.
Haiku costs only $0.25 per million tokens and given the nature of the task we could also use a low-res version of the images. In all, it would cost around $20 to have Haiku triage our images and at 4,000 requests per minute, it would be done in 20 minutes. In the end, we’d have a much more manageable 6,500 images left to send to GPT-4o at a cost of $32.50, which would take another 5 minutes to process. So in 30 minutes and for $50 we’d have an answer to a question that would have taken us many weeks to work through.
This type of automation promises to speed up the research process without affecting the underlying dynamics of what we actually do as historians. With AI, gathering the evidence might happen faster and cost much less than it does today, but the process of analyzing and writing-up the results will largely remain unchanged.
Revolutions Real and Imagined
As frightening as this may sound to some of us, I actually think it will be similar to the way digital photography changed the research process. In the old days (which I vaguely recall from my first research trips to Ottawa more than two decades ago), researchers had to be physically present to go through records. Pencil and paper only, no laptops, no cameras. You could flag records for photocopying, but it was $0.50 a page.
The advent of digital photography a few years later suddenly meant that you could “shoot first and ask questions later”, capturing thousands of images in a few days and then spend weeks pouring over them at home where you did not have to pay extra room and board.
But as ubiquitous as this approach is today, around 2005 I was scolded by a senior historian in the LAC reading room for using a digital camera. In his view, the job of the student was to immerse themselves in the records for months at a time, carefully reading through every page in the archives. He saw my camera as an appalling shortcut. Try as I might, I could not make him understand that that was, in fact, exactly what I was doing!
I didn’t have the money to spend “months at a time” in Ottawa when I lived in Southwestern Ontario, but by making short visits a few times a year to capture thousands of images, I was effectively doing exactly what he wanted me to do, just at home on my computer. The alternative was either taking-on a much narrower topic (which he would not have liked either) or not doing the research at all.
Digital photography made historical research more accessible. At the same time, I think it also provided the opportunity to go much deeper into the sources as it allows us to easily re-read and re-check the evidence based on the accumulation of new information, to re-purpose large bodies of materials for different projects, or to share sources with students.
I think the effects of AI will be similar because to me, the main thing it will do is alter the scope of the possible. Instead of esoteric questions about the transit times of wounded Great War soldiers, imagine getting an LLM to summarize the contents of each document on a reel of microfilm, the pages of a diary, a series of letters, or all those photographs you took last summer at the archives. We can now use it to produce transcriptions—even of handwritten texts—that are as accurate as those done by human transcription services (stay tuned for a future post on this and that software release). It will let us organize our materials more efficiently, draw out hidden connections and linkages, and do deeper research.
Fear not: the use of AI to analyze digital records won’t absolve us from actually reading and knowing the contents of archival documents; that will always remain a constant for our profession whether we capture a digital images or read the paper versions in the reading room. The reality is that it is not really possible to effectively incorporate AI into the research process anyway without having well-grounded, domain specific knowledge of the material. Otherwise, what would your instructions to the LLM actually look like?
Stay tuned as I role out some example programs over the coming weeks that will allow you to try some of these approaches for yourself. The possibilities are endless, terrifying, and intriguing all at once.
As the data is in a preprinted structured form and in many hands, you probably need to have the ability to recognise the structure of the page - it is basically a complex table and there is an assumption that the same group of hands are found over the period of war service of the individual soldier. There two issues: getting a reproduction of the layout as close as possible to the way the data is laid out - the service record - this is how visually you can see the relationships between pieces of data. The ability to tag the metadata (field labels in the table) - name, rank, location…. Would be good. Secondly, you need an interface - a workbench so the transcriber and project team can manage the work, test and run models , etc., without manually running programs. Most institutions would not allow users to run programs. You need a user interface. IT staff get really nervous… security issues, mainly. IT staff need to be able to see what the application is and does. Overall great work, but given you are working with cursive in mostly historical documents, your CERs mostly will be less than 10% no matter what LLM you use. I don’t think you can match the CERs seen in printed materials - there is too much variability in historical and archival documents. Single hands, with a regular style are easy but archival items with many hands, page structures and cursive styles are more difficult.
Fascinating, Mark! I'm in the process of HTR'ing thousands of pages of transcriptions of notarial records and your post inspired me to try to see if it could create a simple spreadsheet with the data. It worked for the first few documents, but not for the whole file (it just doesn't produce any output - its status remains at "analyzing" forever). Any tips? I have zero knowledge of programming, alas.