
Where Do Stochastic Parrots Go When They Die?
Google DeepMind’s new Antigravity Agent and Gemini 3.5 Flash model are going to shift the conversation on AI yet again.


As it’s become clear that agentic AI systems are, indeed, increasingly capable and more reliable, there’s been a palpable vibe shift. Of course, for many people inside AI World, this has been apparent for some time. The stock market also noticed months ago. But so long as AI agents were confined to programmers coding up their own bespoke systems, it wasn’t an experience available to the average person talking to ChatGPT. Understandably, people had a hard time squaring narratives in which “LLMs are just stochastic parrots” with stories about how agentic AI was going to change all forms of knowledge work.
Over the last six weeks, though, two things changed. First, the wide release of Anthropic’s Claude Cowork and then OpenAI’s Codex pulled back the curtain and let everyone else experience agentic workflows. Suddenly, non-programmers were able to ask agents to do things—and saw for themselves that they could often do those things quite well. Second, the underlying models got better, more reliable, and started being updated much faster—probably in part because they were being trained on agentic tasks. Because this happened just as the frontier labs also started providing more free and low-cost access, the gap between the “frontier” and “free” shrunk considerably.
Now that even the most prominent LLM-skeptics have started to admit that tool-based agentic LLM systems might be useful, the stochastic parrot will soon be no more. Of course, people will still quibble about whether LLMs really understand and reason in ways that are recognizable to humans. But if you accept that when an LLM is strapped into the proper harness and given the right tools it can reliably do useful things that only humans could do before, that becomes more of a philosophical than a practical question. That was Alan Turing’s point with the thought experiment he undertook in the Imitation Game 76 years ago: if we can’t actually define what reasoning and intelligence are, then all that matters is whether we can distinguish machine outputs from human outputs. And if we can’t, well…
What Agents Can Do Now
One of the reasons the discourse is going to shift and shift quickly is that the coming months will see the development and release of a range of bespoke, domain-specific agentic tools powered by cheap but highly reliable models. As impressive as Cowork or Codex are, they are general-purpose tools which sometimes falter when it comes to domain-specific tasks, especially those which must be broken down into a number of constituent parts and tackled at scale.
For example, I recently had Cowork look through a few dozen online microfilms each with around 1,000 pages, looking for a few needles in a haystack. It did an excellent job but it took the better part of a week of continuous operation. This is mainly because Cowork is designed to operate sequentially, that is, performing one task at a time, one after another. Now imagine if I could have spun up 50 Coworks all at once.
That is, in effect, what is coming, fueled in part by cheap but highly capable models like Gemini 3.5 Flash and the new Antigravity Agent, released earlier today by Google DeepMind. I had early access to the Antigravity Agent via the Managed Agents API for a couple of weeks (no one at Google has seen or approved what I am writing here). What makes Managed Agents so interesting is that it is a fully agentic system, like Cowork or Codex, except that it is called through an API rather than operating on your desktop. This is important because it makes the system highly flexible and adaptable. Moreover, it will allow developers to build the type of agentic capabilities you get with Cowork or Codex into their own apps, to call them dynamically when necessary—and to push those capabilities even further. Because the system is built on top of Gemini 3.5 Flash, it is comparatively cheap to run: $1.50 per 1 million input tokens (about 750k words) and $9 per million output tokens.
Introducing DeepMind’s Antigravity Agent
The Antigravity Agent is a command-line, sandboxed agent that lives in the cloud. What this means is that it runs on Google’s servers and has access to a terminal window where it can write and compile code, create, store, and manipulate files, and do basically anything it needs to do on a computer to accomplish a given task. The developer and Google also set certain access parameters and guardrails, hence it being “sandboxed”. In this sense, it operates just like Claude Cowork or OpenAI’s Codex, except without a graphical user interface (the program you use on your desktop).
When a developer sets up an Antigravity Agent for a client, they customize the agent to that client’s specific needs, installing tools, skills, and Python libraries that only that client might need. This can also be done dynamically, allowing the Antigravity Agent to develop its own bespoke environment as it works through tasks. Conversations are stored server-side and can be resumed, which means that for a given task, the agent can effectively learn from prior experience. Users can also share environments and conversations, both of which can be persisted (meaning they are stored and can be reused repeatedly), which makes deploying agents to the enterprise or team-based research environments much easier and smoother.
If all this sounds like techno-babble, in a nutshell: the Antigravity Agent makes it cheap and easy to build bespoke, shareable agents for specific types of knowledge work. Developers are going to seize on this to build apps that let researchers and students do a ton of new things. Practically speaking, I could have used the Antigravity Agent to do my microfilm example in a fraction of the time, spinning up dozens of agents to do in minutes what took Cowork days—and what would have taken me many weeks.
Charting Vaudeville Reviews with an Agent
Here is a tangible example of what it can do. Over the past couple of weeks, I’ve worked with a colleague, David Monod, to help him on a project related to analyzing reviews of Vaudeville acts between 1905 and 1925. First, this involved using ArchivePearl to transcribe all the issues of Variety magazine (about 600 issues or 15,000 pages) from Internet Archive as well as a series of online archival managers’ reports (about 9,000 pages). We then extracted all the reviews and put them into a database, generating about 150,000 unique records. We used Gemini 3 to extract metadata from each record, including the various auditory and visual elements described in each review, the audience/reviewer reaction, dates, theatre, etc. For context, this process took a few days to run start to finish, whereas in a previous SSHRC project, Monod and a team of graduate student RAs spent several years completing only a 10% sample of the same record sets. In the end, our database could be searched using conventional keywords and Boolean logic as well as semantically, that is by concept.
To work through this mountain of data, we wired up the search tools to an Antigravity Agent environment which included standalone versions of the complete database files for efficiency, various Python libraries for data analysis (i.e., pandas, Matplotlib, etc.), as well as a Markdown file which described the overall project, the datasets, and the field names in the database as well as how the data was extracted. This allowed us to ask the agent to work with the data to answer questions. In seconds we could generate charts, graphs, and analytical data about any theme we wanted.
Now at this stage, you might shake your head and say to yourself: but don’t LLMs hallucinate? Isn’t that exactly how not to use an LLM? But here’s why agents, and the Antigravity Agent specifically, are going to change the conversation and why that change is going to be such a hard pivot.
Agents, Data, and Reliable Visualizations
It is certainly true that if you give an LLM a massive amount of data and ask it to create a chart, it will do so but it will almost always be spectacularly wrong. Totals will be off, categories will be missed, etc. LLMs make pretty charts now, but they are not reliable on the actual data. Not to get too far into the weeds, but here LLMs usually fail in ways that are actually quite similar to humans if you think about the process. If you asked me to go through those 150k records and create a chart of all the dancing acts from 1905-1924, but told me that I was not allowed to use a spreadsheet, calculator, or even a piece of paper to keep track of what I was doing, I’d certainly make similar mistakes to the LLM. I’m certain I’d produce something that was actually much worse in the end too. That is, though, what we’ve been asking LLMs to do without agentic harnesses. On top of that, up until now, those charts have also typically been drawn with generative AI image-creation models. Although they’ve gotten much better, they still make mistakes translating data into visual images. And mistakes compound. All of this means that asking ChatGPT to graph a dataset is generally not a good idea.
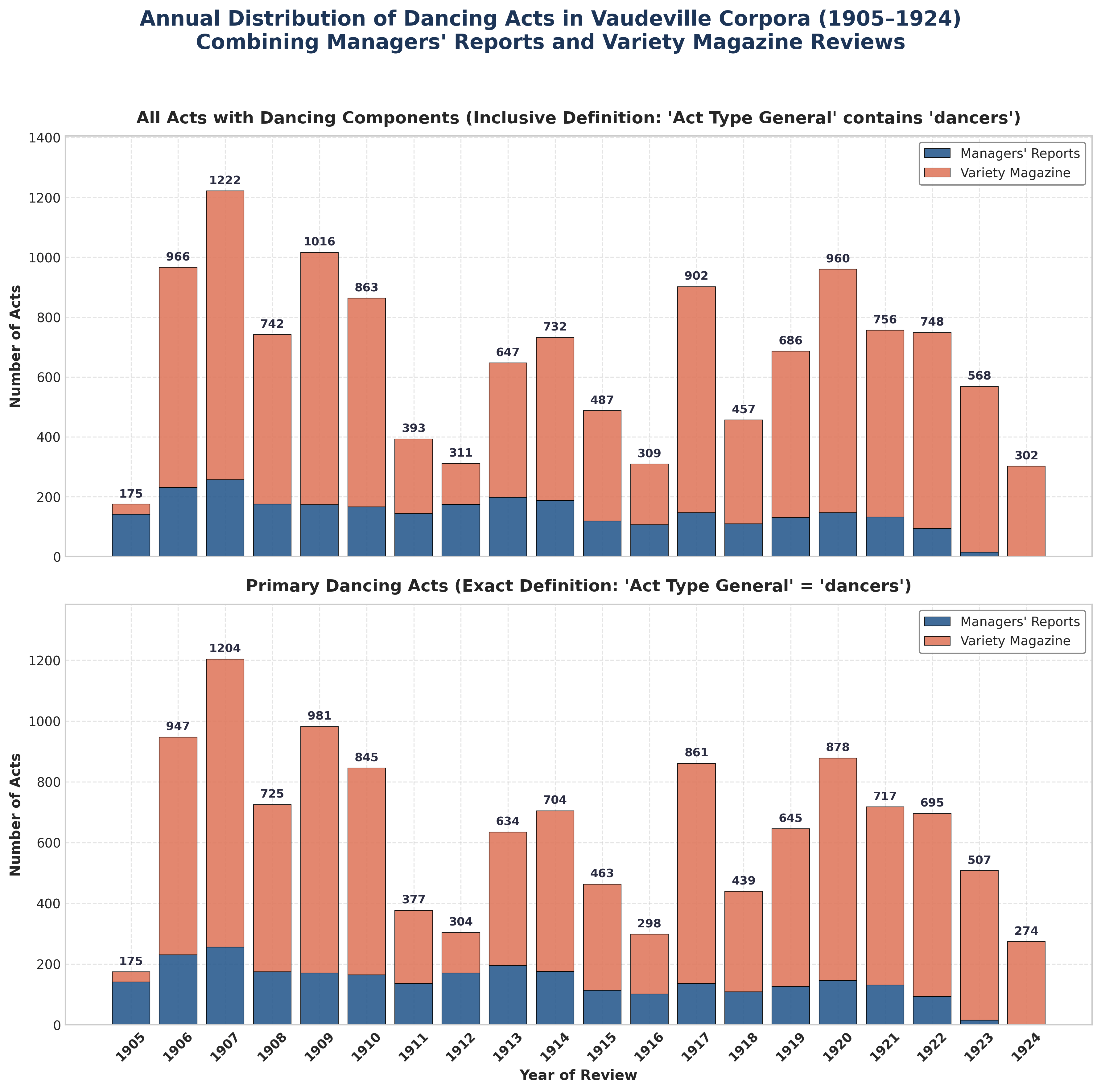
Agentic LLMs don’t have to try and do math “in their head,” though; they write and use code to analyze the data and then they use reliable code, not image models, to generate the charts. In effect, they have access to the spreadsheet via tools and a calculator and scratchpad via code. So when we ask an Antigravity Agent to produce a chart of all the dance acts between 1905 and 1924, the agent doesn’t work from memory or something that someone copied and pasted into a chat window, it uses Python to count the number of acts in the actual database that could be identified with the word “dancers” in the “Act Type – General” field (as well as a wide range of synonyms which it came up with on its own) and then broke that out by year. It then used a Python library, Matplotlib, to translate those numbers into a visual chart. This is exactly what a human would do using Python—or in Excel with a formula and the chart tool. The end result is a chart that is accurate to the dataset.
The integration of Boolean and semantic search tools running over a database is also critical for historians. Once you find a trend you want to explore, you can also use the model to find illustrative examples. Because the conversations and environments persist, you can refer it back to the chart and sub-dataset it created and ask it to find the example that best illustrates a given idea. It does this by searching the actual database itself, in multiple different ways, to find a range of potential examples. The outputs can then be linked back to the dataset, allowing the researcher to quickly verify the outputs.
Think about the possibilities this opens: suddenly you can test any hypothesis in seconds using natural language. Because the investment in time is so small, you can afford to look for whatever you want in the data. Here I think back to a book I wrote on shell shock which relied heavily on a statistical sample of around 400 soldiers. I constantly had to make choices about what trends and themes I would investigate because I couldn’t afford to spend a week charting data on something that I might never use or that just became a footnote in the final book. I imagine that some of those missed long shots might have turned out to be really valuable, though, and now chasing them down would be feasible.
Conclusion
It’s amazing how far this has all come in only three years. In March 2023, Eric Story and I wrote a piece in Active History called “Today’s AI, Tomorrow’s History”. Written just before the release of GPT-4 (but published just after) we tried to imagine how the technology would evolve. “While it is easy to be pessimistic about AI’s effects on the humanities in general and history in particular,” we wrote, “it is worth remembering that it has great potential to speed up some of the more mundane and repetitive tasks we do as historians. Imagine a future in which thousands of pages of handwritten documents are quickly transcribed, proof-read, summarized, and analyzed by AI. Imagine the power of OCR-enabled LLMs if given access to pre-existing archival databases, such as Canadiana, Personnel Records of the First World War, or the Voyageurs Contracts Databases.” At the time, LLMs were not yet multimodal and still had a 4K token context window. We thus thought that such a future was still a long way off—I recall personally thinking it was maybe ten years away. But we’re already there.
Cowork, Codex, and this new Antigravity Agent thus present remarkable opportunities for researchers. With them we’ll be able to do things that were literally impossible just a few years ago. In the main, I think this will involve discovering things about the past by linking record sets like those above, finding needles in haystacks, and reducing the time required to plow through archival data. None of this changes what we do, it only adds new tools to the toolbox while giving us new ways of approaching old questions.
For historians, the question is no longer whether these tools work. Increasingly, they just will. But as history speeds up, we’ll also need to learn to intentionally slow down at the right moments—when defining the data, choosing the tools, interpreting the outputs, and deciding what counts as evidence. And that requires moving on from stochastic parrots to having a real conversation about methodology and norms for using agentic LLMs effectively.
When it comes to HTR/OCR tools,
The problem is that ABBYY FineReader does not cope well with 19th-century printed books from Eastern Europe, even though it is Russian software. And Transkribus is a commercial system and by no means cheap if you need to process large volumes of material. It is probably wiser to invest in eScriptorium/Kraken. But not in every case; if we have several thousand pages of manuscripts from dozens of people, this may lead to the need to retrain many models, which is time-consuming. Gemini, however, reads 19th- and 20th-century handwriting well enough to significantly speed up the work. Of course, LLMs make different kinds of errors than traditional HTR models; one must pay particular attention to proper names and areas with less legible handwriting, where the likelihood of hallucinations is greater.
As a traveler of vibecoding, this was truly fascinating to me (thank you!).