
Introducing Transcription Pearl
A Practical AI Tool for the Automated Transcription of Historical Handwritten Documents with State-of-the-Art Accuracy


One of the things I find puzzling about reactions to AI, is that people often tend to focus on its far reaching but still entirely theoretical effects while ignoring the many smaller, less glamorous but highly practical things that AI can do right now. One of those practical things is transcribing historical handwriting. As we’ll see below, it’s also a good example of how we can use LLMs to do lots of monotonous tasks very quickly that have nothing to do with chatbots. But first we need to get away from the chat interface and find ways to integrate LLMs into software tools.
In this blog post, I introduce Transcription Pearl, an open-source program that transcribes handwritten documents and corrects transcriptions generated by other HTR programs with state-of-the-art accuracy. Depending on how you count errors (more on that below), it can achieve character level accuracy above 98% and word-level accuracy above 96% making it about as accurate as most human transcribers and better than other HTR tools. It also costs 1/50 the amount to use as other popular programs like Transkribus and is about 50 times faster.
Although I was responsible for the programming, the program is the work of many people. It grows out of a larger project I’ve been working on with Lianne Leddy and a team of student researchers who’ve tested its various iterations over the past two years here at Wilfrid Laurier University: Quinn Downton, Meredith Legace, John McConnell, Isabella Murray, and Elizabeth Spence. You can download it and run it today from our GitHub Repository (you’ll need to get an OpenAI, Anthropic, or Google API key too). You can also read a pre-print of the paper we wrote which I’ll link to it throughout this post when it can provide more information.
But first for the more technically experienced readers, full disclosure: the software interface is pretty simple and I imagine the code leaves much to be desired. Please remember that I am a historian and not a professional software developer. But I think that this actually illustrates another really important point: although in February 2023 I had some ancient experience in visual basic and html, I had never written anything in python. ChatGPT and Claude Sonnet-3.5 taught me the language and helped me write the code for Transcription Pearl. That is pretty remarkable and its something that would not have happened without generative AI.
Handwritten Text Recognition and Error Rates
First some essential background. Handwritten Text Recognition (HTR) has been a challenging area of research in computer vision and pattern recognition since the 1960s. Traditional HTR approaches involve a complex, multi-step process in which handwritten documents are digitized and then pre-processed to improve their quality. The text must then be segmented into lines, words, and individual characters before machine learning algorithms can try to identify patterns. While HTR methods have made significant progress in recent years, especially with programs like Transkribus that (at least in part) uses the same underlying transformer architecture as LLMs, they still struggle to generalize from their training data to new handwriting styles. If you’ve ever tried HTR, you’ll know that it can make lots of errors, sometimes so many that it’s not worth the effort.
In the field of HTR, accuracy is typically measured using Character Error Rates (CER) and Word Error Rates (WER). CER represents the percentage of incorrectly transcribed characters, while WER indicates the percentage of words that are incorrectly substituted, added, or deleted. As a rule of thumb, WER is usually about 3 to 4 times higher than CER. Programs like Transkribus typically achieve CERs of 8-25% and WERs of 15-50% on individual’s handwriting they have not seen before in training(1, 2, 3). To achieve a usable level of accuracy, users must fine-tune an HTR model, typically providing around 75,000 words of transcribed text and image pairs for each individual handwriting style they need to transcribe. While fine tuning makes it possible (1, 2) to achieve CERs of 1.5 to 5% and WERs of 6 to 12%, it is probably wasted effort unless you are transcribing an entire collection of single-authored papers.
To put these error rates in context, professional transcription services typically guarantee around 99% accuracy at the word level, meaning 1 out of every 100 words would be transcribed incorrectly. However, this is only under ideal conditions with clear handwriting and high-quality images, which historians will know is the exception rather than the rule. Studies on non-expert human transcription error rates are limited, but research suggests WERs ranging from 4% to 10% for speech transcription and around 10% for paper medical record transcription (1, 2). One of the only studies I could locate on historical transcription reported human WERs as high as 35-43% for non-specialists transcribing early modern Italian documents. Anecdotally, I’ve found that I achieve something like a 1 to 2% CER and 3% to 6% WER on manual transcription.
Here we need to also remember that error rates are not as straightforward as they seem: not all changes between a ground-truth document and transcript are equal. Edits that standardize capitalization, punctuation, and spelling, called emendations in the editorial world, can be entirely acceptable in some circumstances or highly problematic in others depending on the purpose and context of the transcription project. However, substitutions, deletions, or additions that go beyond these things are almost always problematic: think missed words, added words, or writing horse instead of cow in an estate inventory. Editors also need to consider how to handle marginalia, insertions, strikethroughs, dates, and formatting, choices that can also affect how accuracy is scored (should a strikethrough be included in the text or placed in parentheses?). For many applications, such as keyword searching or general accessibility, a higher WER may be okay if most of the errors relate to emendations rather than skipped or misread words. For publishing critical editions, quotations, or detailed analysis, a higher standard is necessary.
Transcription Pearl
Our initial goal with Transcription Pearl was to create a piece of software that could help transcribe handwritten documents to be used in our AI research assistant project. Initially we had success getting LLMs like GPT-4 to correct transcriptions created by conventional HTR programs like Transkribus, but they were not very good at reading handwriting from scratch (and it was too expensive). But as LLMs improved, they started to achieve a surprising level of success, first with GPT-4o, later Sonnet-3.5, and then Gemini-1.5-Pro-002.

Transcription Pearl works by harnessing the flexibility and contextual understanding of LLMs for handwriting recognition tasks. Unlike traditional HTR models that use complex preprocessing and segmentation, it relies on the fact that LLMs can generally find, organize, and then read the text in an image without preprocessing or fine-tuning. To correct transcriptions, we use into the fact that LLMs are also inherently big text prediction machines. This makes them very good at figuring out how to correct erroneous characters and words based on the surrounding context.
In Transcription Pearl users drag-and-drop images into a workspace and select “Transcribe” from a menu; thirty seconds later, the transcriptions appear in an editing box beside the original image. The user can then send the text and image to another LLM to correct errors in the transcription, a process that takes another 30 seconds. Users can also skip the LLM transcription step and import transcriptions generated in programs like Transkribus for automated correction. In a settings menu, users specify the LLM they want to use for both functions from any of the major multimodal OpenAI, Anthropic, or Google models and to customize the instructions given to the models.
Here is what happens behind the scenes. When the user hits “Transcribe”, the program sends the image to an LLM for processing via an API, a secure way of sending information to an external server. The model returns the transcription and Transcription Pearl then extracts the transcription and matches it up with the right image in the workspace. Users can then edit the text and export the results. The key is that all of this happens in parallel, meaning instead of sending one image at a time all the images are sent at once which significantly speeds up the process. Depending on your usage tier with the various LLM providers, you can process hundreds of images a minute.

Like any LLM interaction, the heart of the “programming” is natural language. Both the transcribe and correct functions send the images and/or text to the LLM along with a system message that tells it what to do and a user prompt that organizes the specific task. As a default, the program employs very simple prompts; better results could probably be obtained with some solid prompt engineering. As our goal here was to establish a baseline, though, we kept it straight forward.
Promising Results
While there are several standard HTR datasets available to researchers on the internet, we found that Google’s Gemini model had “seen” most of the documents in training (it spits out a warning when it is asked to “recite” training data). While this warning is unique to Gemini, we have to assume that the OpenAI and Anthropic models were also trained on the same data. So we decided to assemble our own dataset from documents we personally photographed and that we know are not on the internet. The result is a corpus of 50 pages of 18th and early 19th century English documents, totalling about 10,000 words and featuring more than 30 different hands. The characteristics of the images also vary widely: some are taken from microfilms, others were captured with an iPhone or a Cannon SL; a few are blurry and only a couple are truly high quality. In other words, they are pretty representative of the types of images historians use in their research everyday. We are not publishing the set as we want to be able to use it again in future (if we put it on the internet, it will almost certainly be used in training future models and s0 will no longer provide a reliable, common basis of comparison).
The results are pretty impressive. Depending on how you count the errors, Transcription Pearl achieved CERs as low as 5.7% and WERs of 8.9% without any fine-tuning or preprocessing—a significant improvement over specialized HTR software. Even more impressive is what happens when you ladder one LLM onto another: by using LLMs to correct initial transcriptions (generated either by other LLMs or by conventional HTR programs like Transkribus), the tool can produce results with human levels of accuracy.

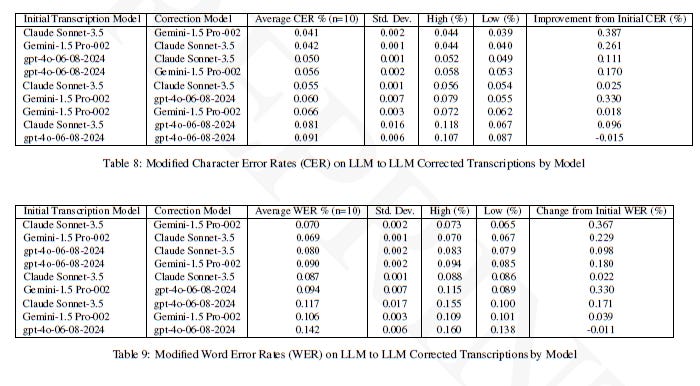
While we tested lots of different model combinations, we found that the most effective pairing was to use Gemini-1.5-Pro-002 for the initial transcription and Claude Sonnet-3.5 for the corrections, achieving an average modified CER of 4.1% and WER of 7%. In this context a “modifed” error rate means one in which we exclude errors of capitalization, punctuation, and corrections to historical spelling.
The best overall results were achieved on Transkribus generated transcriptions corrected by Sonnet-3.5: a modified CER of 1.8% and WER of 3.5%. This means those transcriptions were useable for most “non-publishing” applications, so keyword searching, for readability, etc. That is pretty impressive.
Interestingly, we also found that LLMs could not correct their own transcriptions (something I want to write more about). My intuition is that because transcription errors are derived from probabilities learned in training, the model can’t recognize them as erroneous as they represent highly probable outputs. However, transcriptions generated by models with a different set of weights create errors that are derived from a different set of probabilities and the LLM thus has an easier time recognizing them. As I say, an interesting result but more research is needed.
Error Rates and Types
Error rates were remarkably consistent—which is somewhat surprising for outputs from stochastic models. For our tests, we ran the corpus of documents through the program ten times for each model. If you read the accompanying article, you can look at the complete analysis in our tables but generally the standard deviation in the error rates was low. With Gemini transcriptions, for example, the modified CER ranged between 6% and 7.1% (average of 6.7% and 0.3% Standard Deviation) while the modified WER ranged between 10.2% and 11.7% for an average of 11% (standard deviation of 0.4%). The results for the other models were similar.
Hallucinations were also not a major issue. Most of the errors made by the models were, in fact, pretty human: they misread ambiguous punctuation marks, struggled to discern capital letters, and sometimes corrected historical (or idiosyncratic) spelling errors. Occasionally they added words, mainly missing articles or pronouns to clarify the text. Sometimes they skipped a word. Only rarely did they do something “unhuman”. A handful of times the models substituted a word like “pelts” for “furs”. Again, my intuition is that this is because pelts was a more probable output than furs. But this was a rare occurrence. In a few places where the text was decidedly illegible (passages that I could not decipher myself) the model did it’s best but produced results that were clearly incorrect. Are these hallucinations? Maybe technically they are, but they were reasonable guesses to my eye.
Speed and Cost
What truly sets Transcription Pearl apart is its ability to process documents in batches, dramatically accelerating the transcription workflow. By making parallel API calls to the underlying LLMs, the software can transcribe a set of 50 pages in just 30 seconds—nearly 50 times faster than leading HTR platforms. This batch processing capability is a game-changer for large-scale digitization projects, allowing researchers to quickly and accurately transcribe entire collections with minimal manual intervention.
The affordability of the process is also remarkable. Automated LLM transcriptions cost around 1,500 times less than human transcription services and 50 times less than comparable HTR solutions. To transcript and correct a page using Gemini and Claude costs just $0.0138 per page, making it an incredibly cost-effective solution for individual researchers and institutions alike for most use-cases. Where accuracy is paramount, the cost of correcting a one page Transkribus transcrription would be $0.27 per page—or about half a cent more than the cost of a page of Transkribus transcription.
Conclusion
To download and run the program, you can clone our GitHub repository and create an environment with the necessary libraries. If you don’t know what this means, that is OK: that is where I was two years ago. Ask ChatGPT to help you download and run a python program from a GitHub repository, making sure to explain that you have limited to no understanding of the steps involved. It will walk you through the process, allowing you to ask follow-ups and paste in any errors you might receive for further instructions.
I think Transcription Pearl is a good example of a relatively benign and practical AI tool: although it’s not glamorous, it speeds up the transcription process exponentially while costing next to nothing to use. This use of AI makes it possible digitize massive amounts of archival material quickly, making resources accessible to researchers and the public which should open new avenues for research. And this is probably just the beginning. If the technology continues to improve, we can expect performance to improve as well.
But there are some caveats. Our dataset was relatively small (10,000 words) and while we tried to make it representative of the types of documents we use on a daily basis (as well as representative of the varying quality of the digital images available), others may find that it performs better or worse on their records. We also only tested it on English language letters and legal documents, we did not attempt to transcribe ledgers or financial documents.
So all this is to say that while this is a really promising result, we’re anxious to learn about the successes or failures of others. You can read our full paper here and download the code for the program here (I plan to get a compiled version up soon). Please contact us or better yet, put your results in the comments below!
Wow, that is really interesting as I’ve wondered how it would do on other languages. Great to hear!
Hi Jim, it's always interesting! So you are importing a PDF which has text and images and then correcting the text with Sonnet-3.5...but it looks like the corrections are not going well. Can you send me the PDF?