
When Models Disagree...Transcription Accuracy Improves Significantly
Cross-LLM verification catches 76% of transcription errors, but it only works if we build systems that augment human abilities rather than replace them.


Automated handwriting transcription promises to open-up so many new possibilities for systematic research into the past that it’s hard to anticipate how it will eventually transform our field. In short, from social network analysis to needle in a haystack type tasks, massive transcription projects are going to vastly speedup historical research and make the impossible feasible. But…and this is a critical caveate…only if those transcriptions are truly accurate. If they’re not, errors will compound and any downstream tasks will fail.
Last November I reported that Gemini 3 achieved human-level accuracy on historical handwriting transcription without finetuning. While that was a major milestone in AI research, it is worth remembering that it still tends to make around 4–5 errors per page, not including capitalization and punctuation changes. For lots of tasks this might appear to be “good enough,” but depending on the nature of those errors—whether they’re pure hallucination, erroneous numbers, or misread names—that might still be fatal. It’s still the early days of AI’s relationship with history so it should be no surprise that we’re still trying to figure out what works and what doesn’t and to establish best practices.
Since the fall, I’ve been trying to answer two basic questions around automated transcription: first, can we improve accuracy with better architectures? Second, what types of errors remain and do they betray any underlying biases or LLM specific failure modes? In short, I’ve found that developing the right harness reduces meaningful error rates a further 80% to near 0 and that any remaining errors are insignificant in both their typology or frequency. In this post, I’ll explain how a human centered verification approach works and why designing workflows meant to augment human abilities rather than fully automate them will be central to knowledge-work, at least for the foreseeable future.
False Starts
Last year, the team led by Dr. Lianne Leddy and I (and as of this past April, recently joined by Dr. Carolyn Podruchny), systematically measured Gemini-3-Pro’s performance on a 10,000 word corpus of English language 18th and 19th century records. To do this, we used two metrics: a strict measure in which any difference between the ground truth and test texts counted as an error and a modified test in which we excluded capitalization and punctuation errors (as these are often ambiguous in older documents and don’t tend to change the meaning of the text). On our strictest metric, we found Gemini 3 achieved an average CER of 1.67% and a WER of 4.42% while the modified rates were a CER of 0.69% and a WER of 1.33%.
These numbers translate into about 4-5 errors per page. For comparison, at that time, the best purpose-build programs like Transkribus achieve somewhere around 20% Word Error Rates (WER) without finetuning while expert-human transcription services guarantee a 1% CER on legible text.
In our previous work, we’d found that we could significantly improve error rates by feeding the best baseline transcription (including ones from Transkribus) into another model along with the original images, asking it for corrections. This worked well with Gemini 1.5, Opus-3.7, and GPT-4o where the correction model tended to catch obvious errors while retaining the majority of the baseline text. But what I’ve found is that this approach doesn’t work with newer models.
While the latest generation of LLMs still vary in transcription ability, the problem is that now they are actually all quite capable. Paradoxically, with fewer errors to fix and similar accuracy levels, the most recent frontier models tend to introduce as many errors as they correct. As a result, error rates barely budge or more often, get worse. It’s a weird field and one must get used to the fact that what worked six months ago is probably out of date.
Transcription Verification
Yet better models also tend to present new opportunities. This past winter, a comparison of the Opus, Gemini-Pro and Gemini-Flash transcriptions showed that while they are remarkably similar in aggregate scores, they often tend to get the same words wrong. I started to wonder whether instead of using one model to correct the transcriptions of another, could we take advantage of the general homogeneity of the transcriptions, as well as their focused variance, to identify potential errors? In other words, if we overlay the transcriptions to highlight differences, could we use those differences to catch the remaining errors?
The basic premise is simple: when two different AI models disagree about a word, at least one of them must be wrong, if not both. This is useful, because humans are really good at making focused assessments, the trick is getting the right part of the text in front of our eyes. To do this, I compared a baseline transcription from Gemini 3 Pro with those produced by two other models (Gemini 3.5 Flash and Claude Opus 4.7), and wherever one of the secondary models disagreed with the primary, I flagged that text for review as a potential error. The choice of different model families was deliberate: because the models are built on different architectures and trained on different data, they tend to make different mistakes—in essence, they have different blind spots.
The results were remarkable. Remember that our test corpus contains 10,060 words and our baseline Gemini 3 Pro transcription had 139 non-capitalization and punctuation errors, or about 3 per page. When I overlayed Opus and Flash transcriptions of the same images on the primary transcription, I found a total of 374 differences between them—or about seven differences per page. Those points of disagreement were the potential errors. When they were reviewed against the original document images, I found that they included 106 genuine errors, or about 76% of all the remaining errors in the document. Detecting and correcting them only required a human to review 4% of the text, leaving only 33 error words out of 10,000.

When corrections were made, the end result was a transcription with a strict WER of 3.53% and strict CER of 1.25%; the modified WER was only 0.33% and modified CER of 0.23%. In other words, even by the strictest standards, the transcription was equivalent to that of an expert human. When we omit ambiguous punctuation and capitalization, there was only about 1 error on every other page.
Keeping Humans in the Loop
So how does this work in practice? Unlike earlier tests which you could run yourself on Gemini’s AI Studio, Claude Code, or Codex, to make this approach feasible you need two different API keys (one for Google and one for Anthropic) as well as a visual user interface that lets a human do the actual comparison. This is where building apps that support bespoke workflows for AI becomes so crucial. And it’s also why humans remain essential.
As shown in Figure 2, to make human review quick and relatively easy, we can display the transcriptions and original images side-by-side in a graphical user interface (GUI). We can then use Gemini-3.5-Flash’s image analysis capabilities to visually flag both potential errors in the transcription as well as the corresponding text in the original image. This allows users to check errors at a glance, taking only a few seconds to review and correct each potential error.
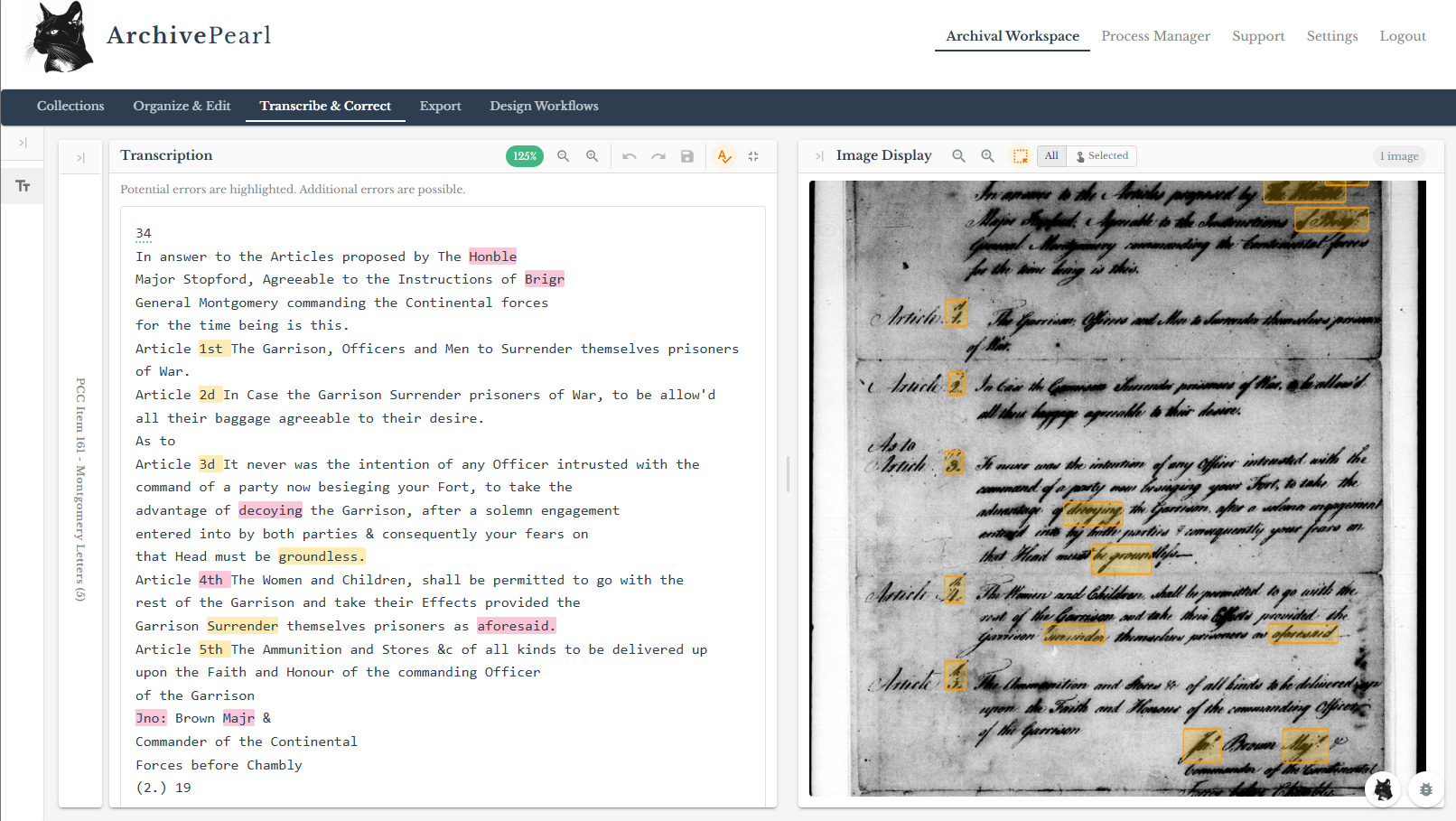
I recently built this functionality into ArchivePearl, which is the web version of the open-source Transcription Pearl software our team released last year. ArchivePearl is designed to streamline the transcription and editing process and to allow people to use the technology who don’t have access to API keys or the ability to install a program locally. It’s a research tool operated on a cost-recovery basis with billing through Wilfrid Laurier University and it’s currently in beta testing. If you want, you can sign-up for your own trial account which provides some free credits to experiment with.
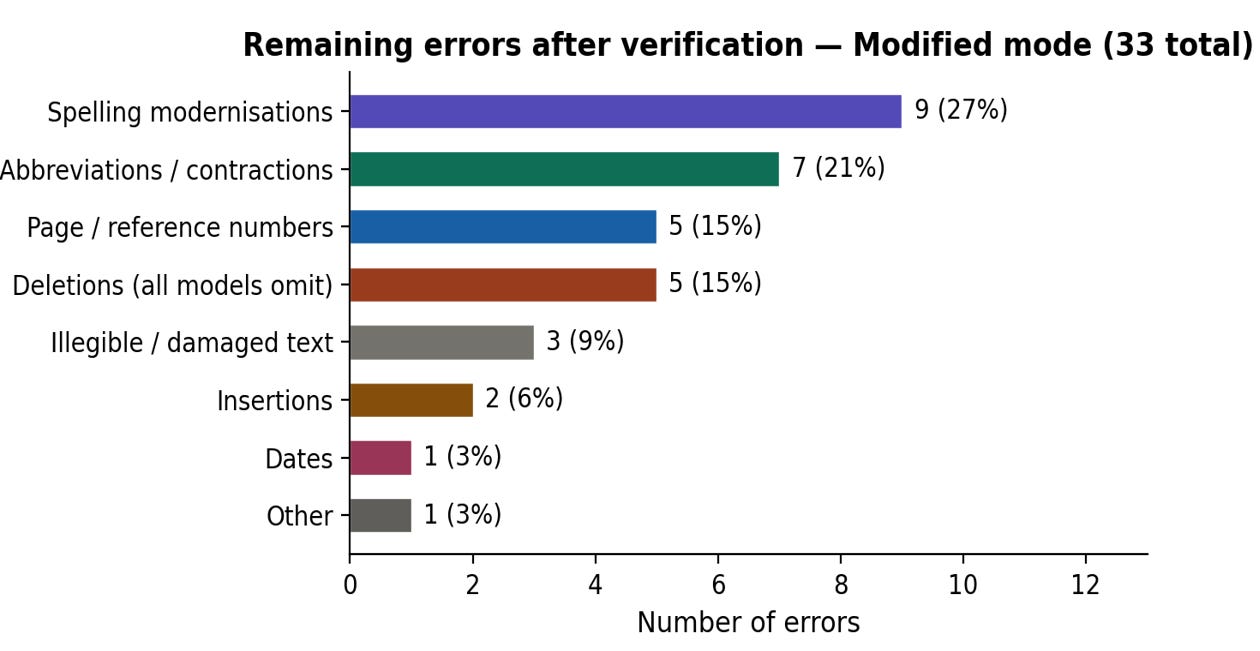
The remaining 33 errors are words on which all three models incorrectly transcribe the text in the same erroneous way. As is clear from the chart below, about a third are spelling modernizations/corrections where all three models converge on the same incorrect reading, such as “Moose” instead of “Mooss” as it appears, incorrectly spelled in the original. Because the models are normally able to correctly transcribe historical spellings, these errors almost certainly are “out of distribution”, that is spellings which are highly improbable given the model’s training data.
Another third are things like page numbers and words where the original page is damaged and thus illegible. Here the discrepancies are more often in how the models handle that illegibility, rather than with its reading of the text itself (ie pow[er] vs pow vs [illegible]). The remainder are a mixture of misread dates and numbers (3) or small insertions (2) and deletions (5).
What I did not find matters just as much as what I found above. There were no hallucinations or significant errors that would change the meaning of the text in any of the transcriptions. The majority were, in effect, typos. This marks a substantial shift from where we were only a couple of years ago when models would sometimes hallucinate text that was not on the page, inventing whole sentences and paragraphs. That is no longer happening, at least not at a frequency greater than 1 in 10,000 words.
Human Augmentation versus AI Automation
In the late 1950s and early 1960s, during the so-called Golden Age of Artificial Intelligence, two competing visions of AI integration vied for acceptance. On the one hand, researchers like John McCarthy argued that artificial intelligence should, in effect, be developed to automate human intellectual work end-to-end, with computers eventually becoming drop-in replacements for people. Others like, J.C.R. Licklider and Douglas Engelbart, put forward a very different vision, one in which machine intelligence would be integrated into human workflows, primarily used to augment human abilities, rather than replace us.
For most of the past sixty years, augmentation won out because machines were never flexible enough to fully automate tasks that required reasoning. That’s starting to change, of course, so the debate has begun anew with greater impetus. At its heart is the question of how much intellectual autonomy and control people are willing to trust to machines. But there is a paradox at the heart of AI use. Automation has value precisely because it speeds things up and reduces costs. But the trade-off is that we lose the ability to oversee the underlying process which, in many fields, can make validation difficult if not impossible. This then requires time and effort to either validate results or remediate the effects of bad AI use. What good, then, are AI outputs that no one trusts?
What we see above is an example of a process designed to keep humans in the loop—one intended to augment our historical work with AI rather than replace it. By overlaying transcriptions to compare the outputs of various AI models, we can easily skim the 96.5% of the text on which the models agree, focusing our time and efforts on the 4% that actually requires human attention. This preserves the benefits of AI, specifically speed and cost efficiency, while ensuring that humans can also trust the outputs. Such a verification process based on model consensus can be employed in any area of non-deterministic knowledge work so long as the tasks are structured, well described, and properly staged or segmented.
This approach also has the benefit of prioritizing human labour. While it changes what human research assistants might specifically do as transcriptionists—just as it will certainly increase their throughput—it still requires trained people with disciplinary expertise. It also has the added virtue of focusing attention back on the text itself and away from the AI. Researchers worry what will happen if we come to rely too heavily on AI, that future generations will become deskilled in critical areas. This is another reason why we should build and prioritize AI systems that seek to augment human abilities rather than fully automate them.
At the same time, what I’ve described above should remind us to think critically about what we actually want to automate because it can be a case by case choice. Archives and historians should use automated transcription to make collections more accessible, assured that if they use the correct harness transcriptions will be “good enough” for most purposes. But those purposes are discreet from the work of historians producing critical editions of the same text—or any other type of work that requires precision and in-depth interpretation. Such projects exist for a different, essentially human purpose and while AI transcription might provide a starting point, that will be all.
As transcription error rates effectively approach 0, it opens a whole new world of possible use cases for AI that involve doing something with an essentially accurate underlying transcription. Full text search, geolocation, metadata extraction, and data compilation all become useable if we can trust the underlying data. But this requires carefully building a historical AI research stack—to borrow a phrase from the software world—from the ground up, piece by piece, making sure that at each stage we’re on a solid foundation. For the foreseeable future at least, this means building systems that augment human abilities, rather than replacing them. And this will be true in most knowledge work fields, not just history.
I noticed in this work you still relied on Gemini 3 Pro. Have you evaluated whether latest AI models (3.1 pro or the presumably forthcoming 3.5 api) serve to reduce the CER/WER rates or whether 3 pro preview is some kind of sweet spot that isn't too smart and isn't too dumb. The need to use low thinking levels and low temperature to achieve the best results sort of implies that this might be the case. At the very least it's worth investigation since as of my comment 3.0 Pro Preview has been shut down.
Edit: Nvm. I see on closer reading that you only kept the 3 pro preview as a baseline and used 3.5 flash in this followup. One thing I don't think you mentioned was whether 3.5 flash alone (not overlayed with opus) produced a meaningfully better CER/WER rate. Was that something you investigated?
This method works well for handwritten text in English. Unfortunately, my tests show that no model can match Gemini when it comes to recognising handwriting in Polish (and probably other languages outside the most popular group as well). So, all that remains for me to do in my app is to look for differences in the transcription between Gemini 3 Pro and Gemini 3.5 Flash.
One risk is the reliance on a closed commercial solution over which we have no control. The volatility of this new technology means that what works today for Gemini 3 Pro may not work for Gemini 4. And when Google discontinues a particular model, we are left with nothing. Is the ability to read old manuscripts valuable enough to the company that it will continue to develop and maintain this feature in its models?
That is why I am also looking into open-source models designed for historical document transcription, such as Churro. I am also exploring the option of fine-tuning models such as Qwen-VL.